Building a Temporal Knowledge Graph from Wikipedia: A Formula 1 Case Study
Exploring how to capture time-aware relationships in knowledge graphs using F1 data, OpenAI's API, and Neo4j
Most knowledge graphs represent relationships as static facts: "Lewis Hamilton has a race engineer Peter Bonnington." But this misses crucial temporal context - when did this relationship exist? Did it change over time?
This post documents building a temporal knowledge graph that preserves when relationships occurred, using Formula 1 data as a test case. The system extracts facts from Wikipedia, stores them with temporal properties in Neo4j, and allows natural language querying.
What we'll cover: Building a pipeline from Wikipedia text to temporal graph queries, handling time-aware fact extraction, and comparing rule-based vs. LLM approaches for query processing.
The Temporal Problem in Knowledge Graphs
Standard knowledge graphs excel at representing "what" and "who" but struggle with "when." Consider this relationship:
Lewis Hamilton → race_engineer → Peter Bonnington
This tells us about the relationship but not:
- When it started or ended
- Whether it changed over time
- How to query for "Who was Hamilton's engineer in 2017 specifically?"
In domains where relationships evolve — sports, business, politics — this temporal gap limits the graph's usefulness. A temporal knowledge graph addresses this by treating time as a first-class property:
Lewis Hamilton → race_engineer(2014-2024) → Peter Bonnington
Now we can answer questions like "Who was X's engineer during their championship year?"
Project Scope and Data Selection
Rather than attempting comprehensive coverage, I focused on a small, manageable dataset to validate the approach:
Selected Wikipedia pages:
- Drivers: Lewis Hamilton, Max Verstappen, Sebastian Vettel
- Teams: Mercedes-AMG Petronas, Red Bull Racing, Scuderia Ferrari
- Seasons: 2017, 2020, 2021 Formula One Championships
Why start small: With 10 carefully chosen pages, I could debug extraction issues and validate the pipeline before scaling up.
Reproducibility considerations: I tracked Wikipedia revision IDs to ensure anyone can reproduce the exact dataset:
{
"title": "Lewis Hamilton",
"revision_id": 1194567234,
"timestamp": "2024-01-15T14:32:00Z",
"extracted_at": "2024-01-20T10:15:00Z"
}
System Architecture
The pipeline consists of four main components:
- Wikipedia ingestion with revision tracking
- Triple extraction using OpenAI's API with temporal annotation
- Graph storage in Neo4j with time properties
- Query interface supporting natural language input
Each component is modular and can be developed and tested independently.
Implementation Details
Wikipedia Data Extraction
The ingestion process captures both content and metadata for reproducibility:
def get_page_content(self, title: str) -> Optional[Dict]:
content_url = f"{self.base_url}/page/html/{title}"
response = requests.get(content_url)
revision = self._get_revision_info(title)
return {
'title': title,
'revision_id': revision['revid'],
'clean_text': self._clean_html(response.text)
}
The system saves both raw content and cleaned text, along with revision metadata for future reference.
Temporal Triple Extraction
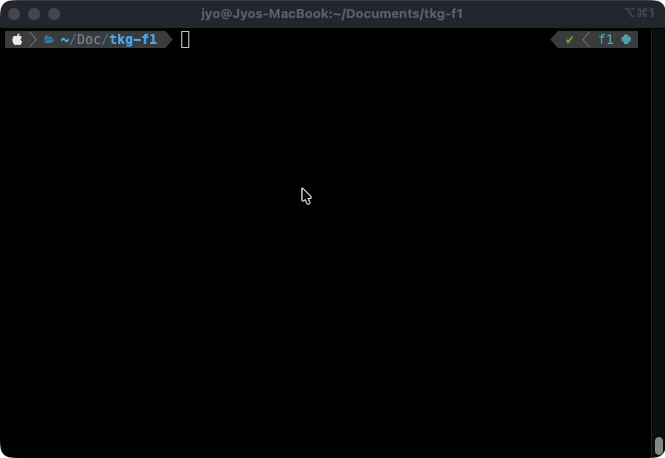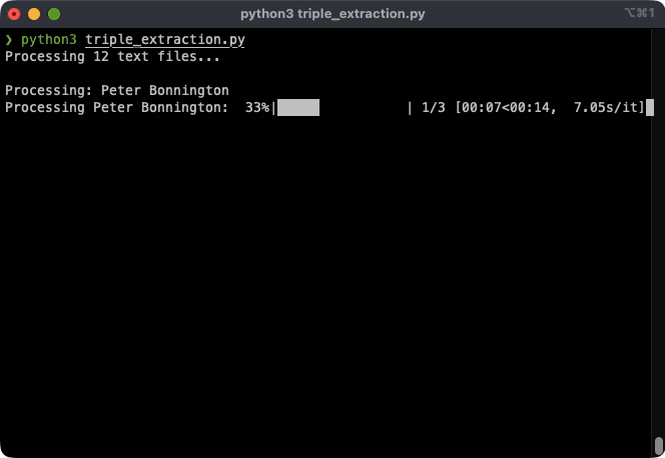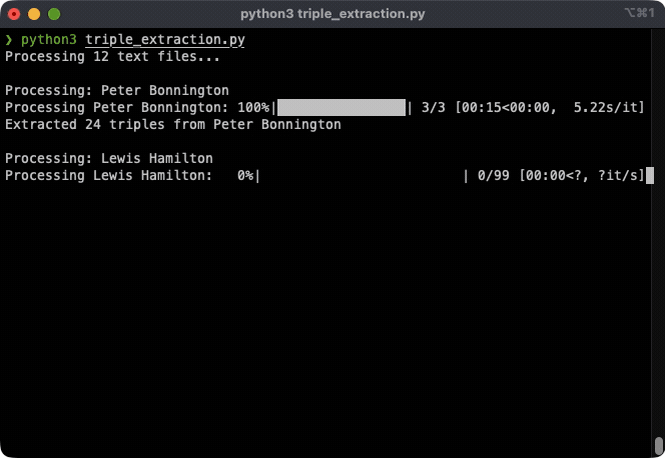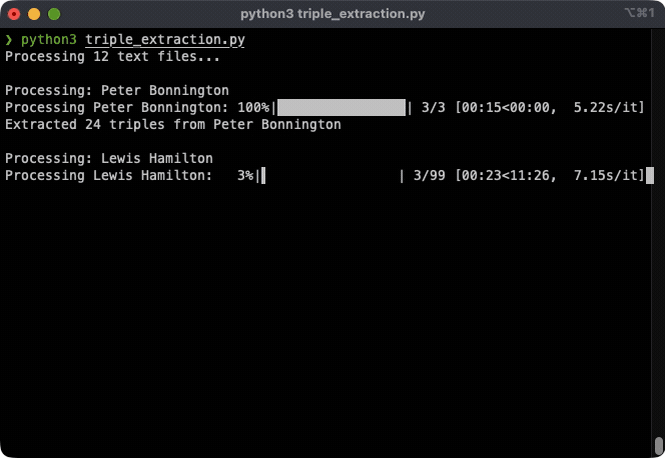
I used OpenAI's GPT-4o-mini to extract structured facts from natural language. A more recent model is likely to perform a better extraction. However, to keep the project cost at minimum, I chose the 4o-mini model. Given this input:
"In 2017, Lewis Hamilton won his fourth championship while driving for Mercedes, with Peter Bonnington as his race engineer."
The system extracts:
[
{
"subject": "Lewis Hamilton",
"predicate": "won_championship_in",
"object": "fourth championship",
"year": 2017
},
{
"subject": "Lewis Hamilton",
"predicate": "had_race_engineer",
"object": "Peter Bonnington",
"year": 2017
}
]
Temporal annotation: Years are extracted using regex patterns that identify temporal expressions in context:
def extract_year_from_sentence(self, sentence: str) -> Optional[int]:
patterns = [r'\b(19[5-9]\d|20[0-3]\d)\b', r'in\s+(19[5-9]\d|20[0-3]\d)']
# Matches: "in 2017", "during 2020", "2017 season"
Cost analysis: Processing 10 Wikipedia pages cost approximately $0.02 in API calls, with GPT-4o-mini achieving ~97% accuracy in triple extraction.
Graph Storage in Neo4j
Relationships are stored with temporal properties as first-class attributes:
MERGE (subj:Entity {name: $subject})
MERGE (obj:Entity {name: $object})
MERGE (subj)-[r:RELATION {
type: $predicate,
year: $year,
source_page: $source_page
}]->(obj)
This enables efficient temporal queries:
WHERE r.year = 2017for specific yearsWHERE r.year >= 2015 AND r.year <= 2020for ranges- Track relationship evolution over time
Query Processing
The system uses a two-tier approach for converting natural language to Cypher queries:
Rule-based patterns handle common query types:
pattern = r"who was (.+?)'s? race engineer (?:in|during) (\d{4})"
# Generates appropriate Cypher for "Who was Hamilton's race engineer in 2017?"
LLM fallback handles complex temporal reasoning: For questions like "Who was Hamilton's engineer when Max won his first title?", the system generates multi-step queries that first determine when Max won (2021), then find Hamilton's engineer for that year.
Results and Performance
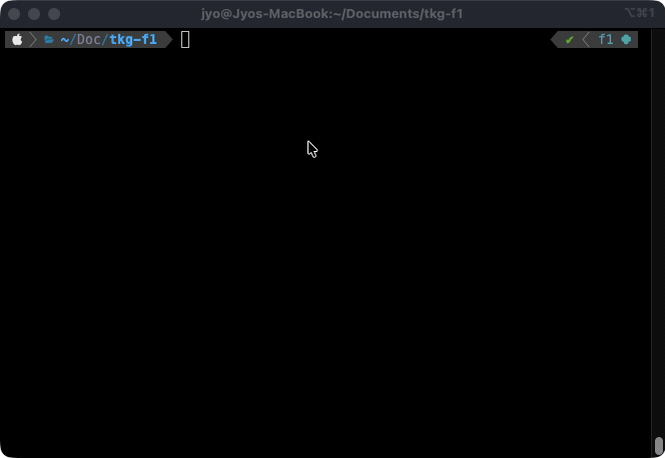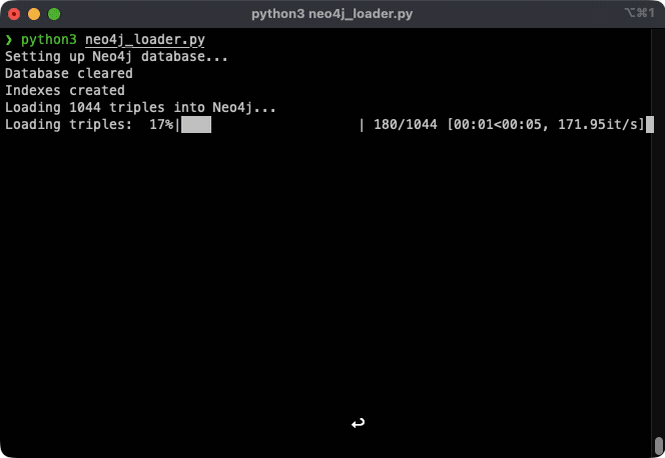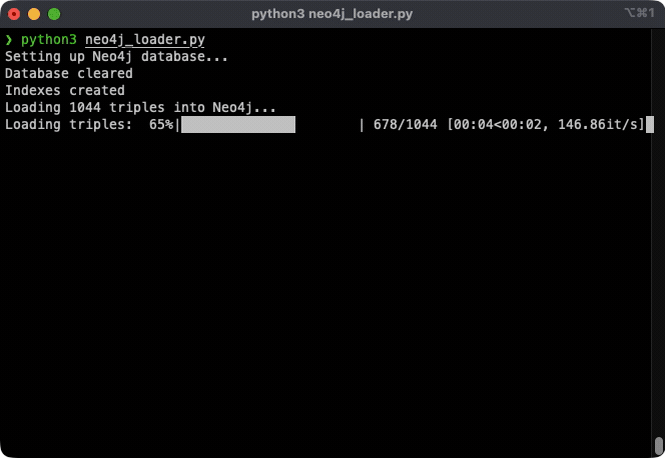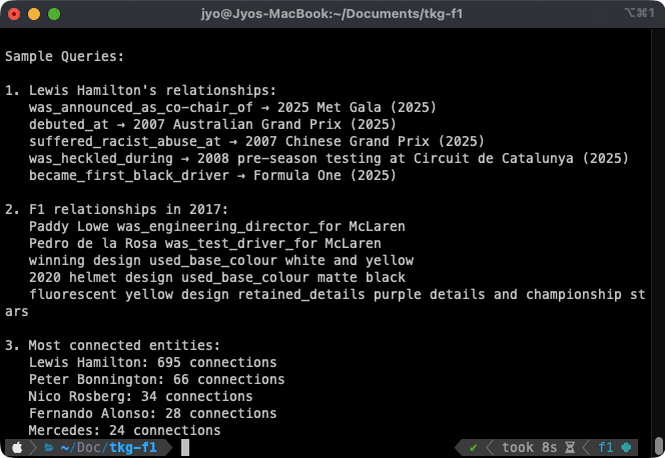
The system successfully answers various temporal queries:
Simple temporal lookup:
Q: "Who was Lewis Hamilton's race engineer in 2017?"
A: Peter Bonnington
Query time: ~40ms
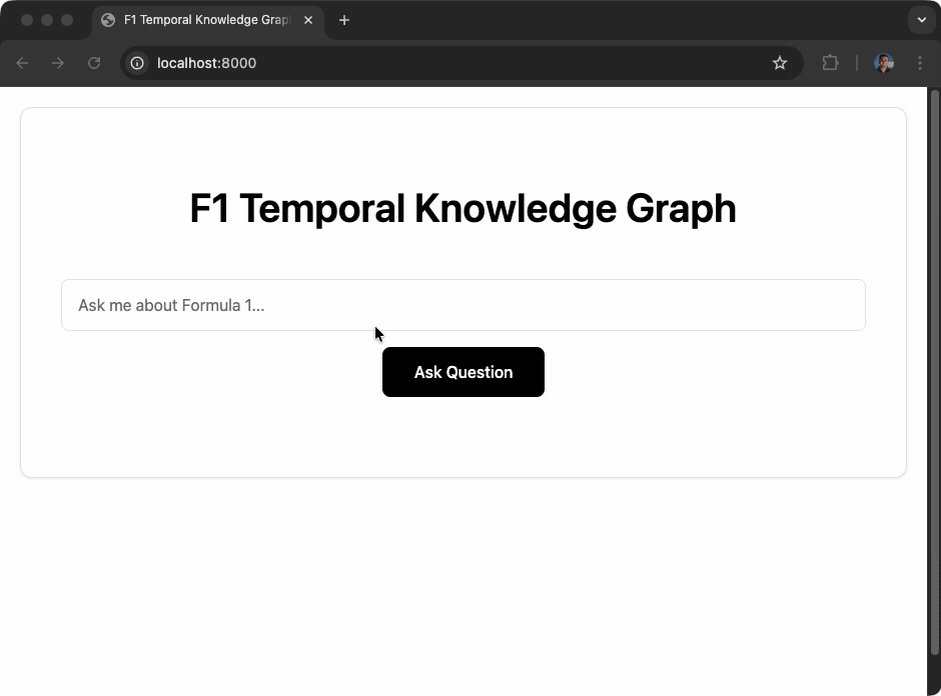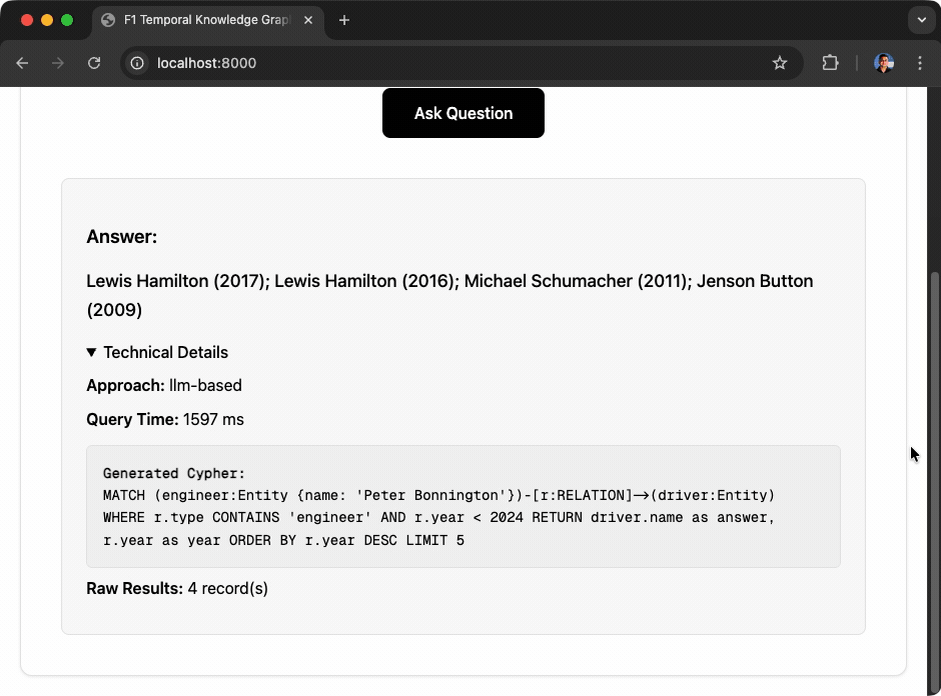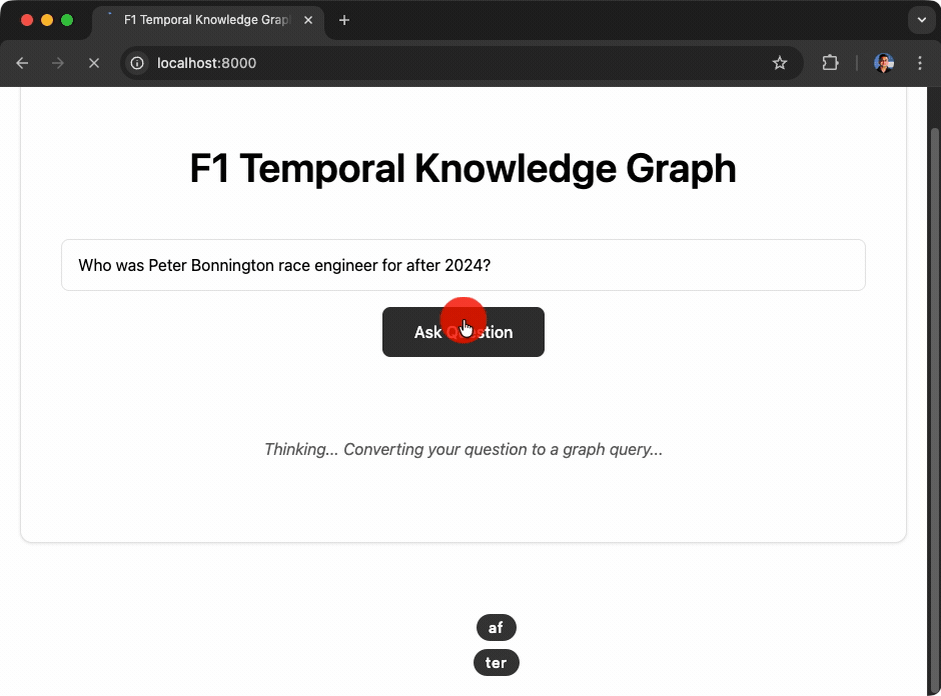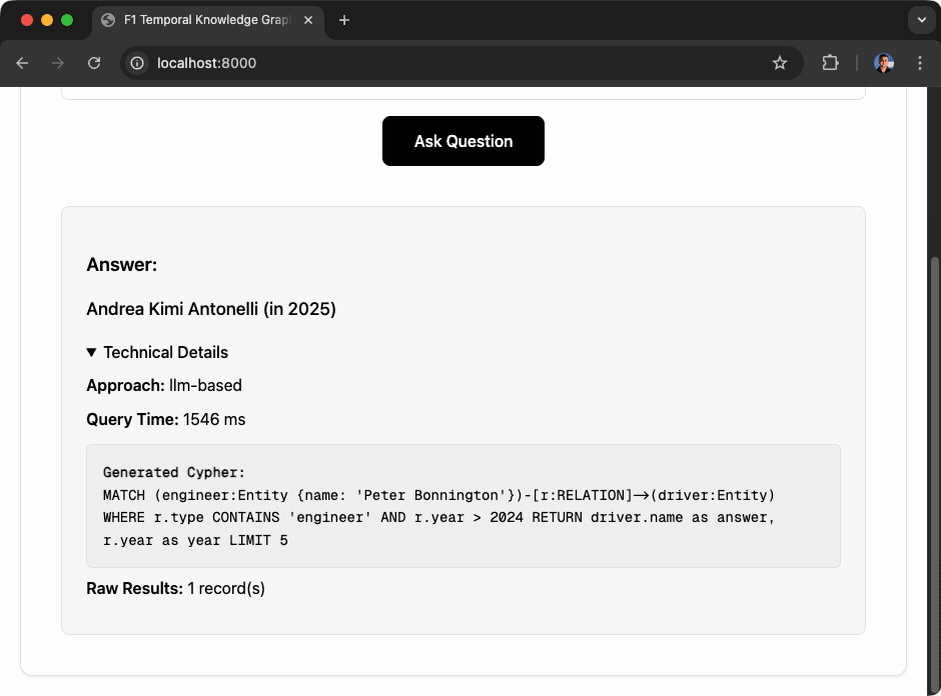
Time Series analysis:
Q: "Who was Peter Bonnington race engineer for before 2024?"
A: Lewis Hamilton, Michael Schumacher, Jenson Button
Q: "Who was Peter Bonnington race engineer for after 2024?"
A: Andrea Kimi Antonelli
Succession queries:
Q: "Who replaced Felipe Massa at Williams in 2017?"
(Demonstrates temporal reasoning about personnel changes)
Performance characteristics:
- Neo4j query execution: ~40ms
- LLM query generation (when needed): ~600ms
- Total response time: <1 second
Lessons Learned
Data Strategy Matters
Working with 10 focused pages revealed extraction edge cases more efficiently than a larger, noisier dataset would have. This allowed rapid iteration on extraction prompts and validation logic.
Time as Infrastructure
Adding temporal properties transforms the graph's capabilities fundamentally. A single year field enables complex temporal reasoning that would be impossible with static relationships.
Hybrid Query Processing
The rule-based + LLM approach balances predictability with flexibility:
- Rules handle 80% of queries with zero cost and 100% reliability
- LLM fallback covers edge cases with 97% accuracy at minimal cost
Reproducibility Requirements
Capturing Wikipedia revision IDs proved essential. Wikipedia articles change frequently, making exact reproduction impossible without version tracking.
Future Directions
Scale expansion: The approach could extend to all 74 F1 seasons (1950-2024) or other domains where relationships evolve over time.
Enhanced temporal reasoning: Adding support for date ranges, overlapping relationships, and temporal inference rules.
Multi-modal integration: Incorporating race footage, lap time data, and other temporal data sources.
Performance optimization: Comparing Neo4j with specialized temporal graph databases like ChronoGraph.
Technical Implementation
The complete system is available as open-source code with:
- Modular Python components for each pipeline stage
- Sample data for immediate testing
- Project documentation
GitHub Repo Link: https://github.com/jyotiska/tkg-f1
Requirements: Neo4j Desktop, OpenAI API access, Python 3.8+
Conclusion
This project demonstrates that temporal knowledge graphs can be built using readily available tools and APIs. The key insight is treating time as a first-class property rather than an afterthought.
While this F1 example uses a small dataset, the principles apply broadly to any domain where relationships change over time. The combination of LLM-based extraction with graph database storage provides a practical approach to capturing and querying temporal knowledge.
The system successfully bridges the gap between unstructured Wikipedia text and structured temporal queries, showing how modern AI tools can enhance traditional knowledge representation approaches.
The complete code, data, and documentation are available on GitHub under an MIT license. The project serves as a starting point for exploring temporal knowledge graphs in other domains.