I created a tiny language model from scratch
I have been using large language models for a little over 3 years now, ever since ChatGPT was announced. In these three years, I witnessed how AI took over the world and opened up possibilities on how you can use these language models for your own use case. I have tried and tested probably every major LLM available in the market, in both personal and professional scenarios.
Lately, I have been meaning to peek under the hood and understand how a language model actually works. The only way to understand this fully is to build one. I decided to follow along with a wonderful YouTube video from Andrej Karpathy and ended up creating a very small proof-of-concept decoder-only language model. It's a two-hour walkthrough where he codes up a small language model step by step. My goal wasn't to build anything useful. I just wanted to finally understand what's happening under the hood. As of writing this blog post, this video has over 6.5 million views!
The Setup
The idea is pretty simple. You take a bunch of text, and you train a model to predict the next character. That's it. If you show it "To be or not to b", it should learn that "e" probably comes next.
For training data, I used a 1MB text file containing all of Shakespeare's works. It's small enough to train on my MacBook and interesting enough to see if the model learns anything.
The model itself is a "decoder-only transformer". A decoder-only transformer is a type of AI model that predicts the next word in a sentence based on the words before it. It reads text from left to right and generates output one token at a time. It's the same basic architecture behind GPT-2 and GPT-3. Obviously mine is way smaller. We're talking a few million parameters versus GPT-3's 175 billion. But the pieces are the same.
The Parts That Actually Matter
I'm not going to explain everything (watch the video for that), but here's what finally clicked for me.
Tokens are just numbers
The model can't read text. It only understands numbers. So first you convert each character to an integer. Shakespeare uses 65 unique characters — letters, punctuation, spaces, newlines. Each one gets a number. "Hello" becomes something like [20, 43, 50, 50, 53].
Real models like GPT use fancier schemes where they break words into chunks. But character-level is simpler and it works fine for learning.
Attention is about tokens looking at each other
This was the part I struggled with the most. Before transformers, models processed each position kind of independently. Attention lets each token look at all the tokens that came before it and figure out which ones matter.
Each token creates three things: a query ("what am I looking for?"), a key ("what do I have?"), and a value ("what should I share?"). Tokens with matching queries and keys pay more attention to each other. The trick is you mask out future tokens so the model can't cheat. When predicting the next character, it can only look backward.
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
Setting future positions to negative infinity makes them disappear after softmax.
Blocks stack communication and computation
A transformer block does two things. First, tokens talk to each other through attention. Then each token processes what it learned through a small feedforward network.
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
That x + ... pattern is called a residual connection. You add the output back to the input. This makes deep networks much easier to train because gradients can flow straight through during backpropagation.
Stack a few of these blocks and you have a transformer.
Training It
I had to dial down the settings from Karpathy's video because I was running on a MacBook instead of a proper GPU.
batch_size = 16
block_size = 256 # how many characters of context
n_embd = 256
n_head = 4
n_layer = 3
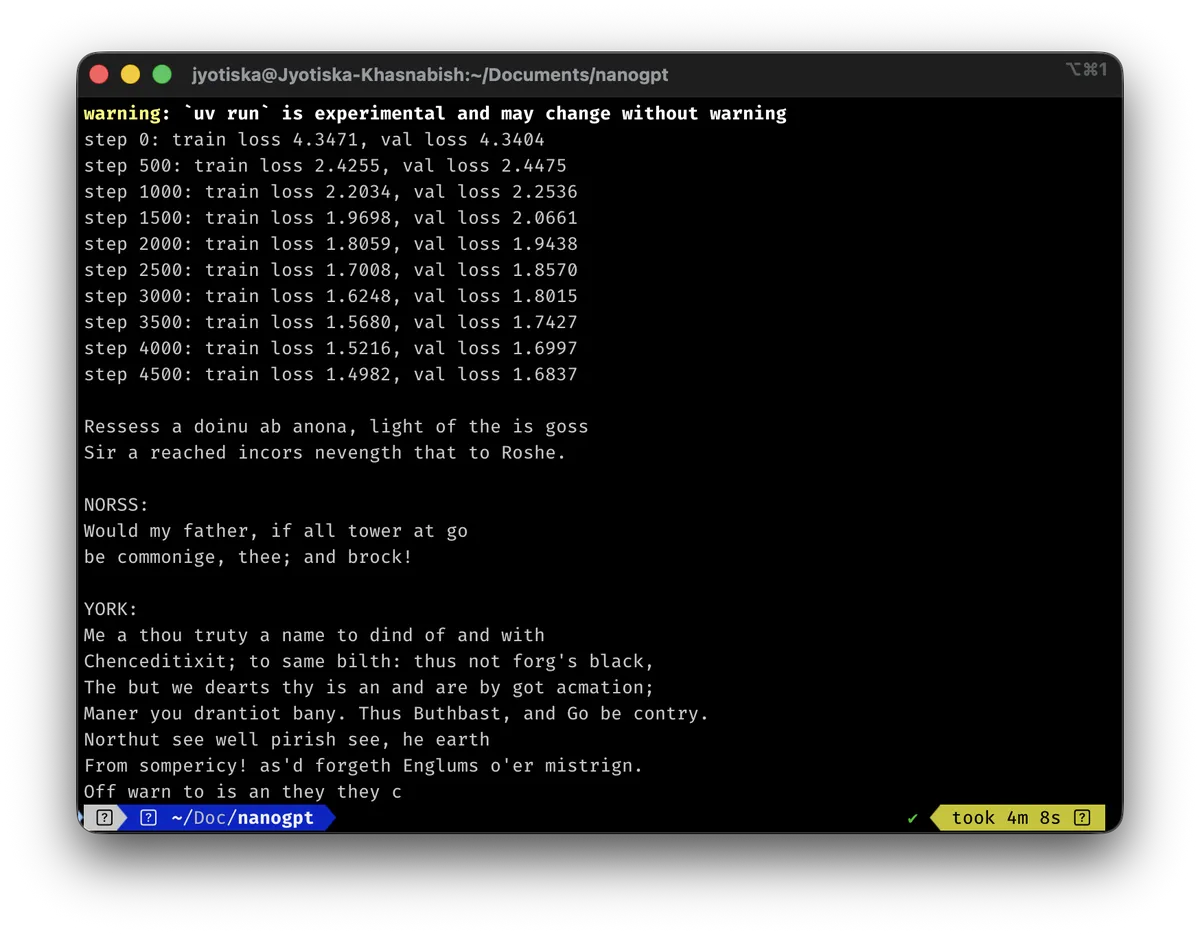
The training loop is simple. Grab random chunks of Shakespeare. See how wrong the model's predictions are. Adjust the weights. Repeat 5000 times.
I watched the loss go from around 4.7 (basically random guessing) down to about 1.5. It was learning something.
What It Produced
After training, I had it generate 500 characters. Here's what came out:
NORSS:
Would my father, if all tower at go
be commonige, thee; and brock!
None of this is real Shakespeare. The model made it up. But it learned the format. Character names in caps, colons, dialogue that sounds vaguely old-timey.
It has no idea what any of these words mean. It doesn't know Norss is a place or that kings have subjects. It just knows that certain patterns of characters tend to follow other patterns.
That's what language models do. Pattern matching at a scale that produces coherent-looking text.
What I Learned
Building this changed how I think about LLMs. Here are the things that stuck with me:
There's no magic here. Before this project, transformers felt like black boxes. Now I see they're just matrix multiplications arranged in a clever way. Attention is a weighted average. Feedforward layers are just linear transforms with an activation function. The "intelligence" comes from scale and training data, not some mysterious algorithm.
Prediction is all these models do. My tiny model predicts the next character. ChatGPT predicts the next token. That's the whole game. Everything else — following instructions, answering questions, writing code — emerges from getting really good at prediction.
Scale changes everything. My model has a few million parameters and trained on 300,000 tokens. GPT-3 has 175 billion parameters and trained on 300 billion tokens. That's roughly a million times bigger on both axes. Same architecture, completely different capabilities.
Fine-tuning is a separate step. My model just babbles Shakespeare. It doesn't answer questions or follow instructions. ChatGPT starts with a model like mine (but huge), then goes through additional training to make it act like an assistant. That's a whole other process involving human feedback and reinforcement learning.
The "hallucination" problem makes more sense now. These models don't know what's true. They know what text looks like. If a pattern is plausible, they'll generate it — whether it's factually correct or not. My model invents fake Shakespeare characters with confidence. Bigger models do the same thing with fake facts.
What I Took Away
The architecture isn't that complicated. Attention, feedforward layers, residual connections, layer norm. Once you see the pieces, you realize the "magic" of LLMs is mostly scale. Train a model like mine on the entire internet instead of one Shakespeare file. Make it a thousand times bigger. Add some fine-tuning to make it act like an assistant. That's roughly how you get from my toy to ChatGPT.
I also have a better intuition now for why LLMs behave the way they do. They're not reasoning. They're predicting what text comes next based on patterns they've seen. Sometimes that produces something brilliant. Sometimes it hallucinates nonsense. Both make sense once you see what's actually happening inside.
Building this took me a weekend. Most of that was rewatching parts of the video. If you've been curious about how this stuff works, I'd really recommend trying it yourself.